译自
ZooKeeper是一个用于分布式应用的开源分布式协调服务。它提供了简单的原语集合,分布式应用可在这些原语之上构建用于同步、配置维护、分组和命名的高层服务。ZooKeeper的设计使得编程容易,并且使用类似于广泛熟知的文件系统目录树结构的数据模型。它运行在Java环境中,但是有Java和C语言绑定。
分布式协调服务是出了名的难得编写正确,很容易出现竞争条件和死锁之类的错误。ZooKeeper的动机是减轻为分布式应用开发协调服务的负担。
1 设计目标
1.1 简单
ZooKeeper让分布式进程可通过共享的、与标准文件系统类似的分层名字空间相互协调。名字空间由数据寄存器(在ZooKeeper世界中称作znode)构成,这与文件和目录类似。与用于存储设备的典型文件系统不同的是,ZooKeeper在内存中保存数据,这让其可以达到高吞吐量和低延迟。
ZooKeeper的实现很重视高性能、高可用性,以及严格的顺序访问。高性能意味着可将ZooKeeper用于大的分布式系统。可靠性使之可避免单点失败。严格的顺序访问使得客户端可以实现复杂的同步原语。
1.2 自我复制
与它所协调的进程一样,ZooKeeper本身也会试图在一组主机间进行复制,这就是集群。
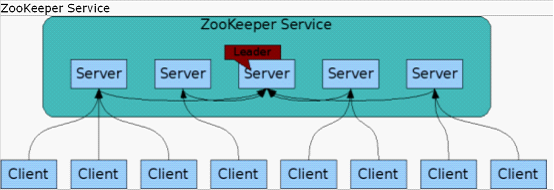
组成ZooKeeper服务的各个服务器必须相互知道对方。它们在内存中维护状态和事务日志,还在永久存储中维护快照。只要大部分服务器可用,ZooKeeper服务就是可用的。
客户端连接到单个ZooKeeper服务器。客户端维持一个TCP连接,通过这个连接发送请求、接收响应、获取观察事件,以及发送心跳。如果到服务器的TCP连接断开,客户端会连接到另一个服务器。
1.3 顺序访问
ZooKeeper为每次更新设置一个反映所有ZooKeeper事务顺序的序号。并发操作可使用序号来实现更高层抽象,如同步原语。
1.4 高速
在读操作为主的负载下特别快。ZooKeeper应用运行在成千上万台机器中,在读操作比写操作频繁,二者比例约为10:1的情况下,性能最好。
2 数据模型和分层的名字空间
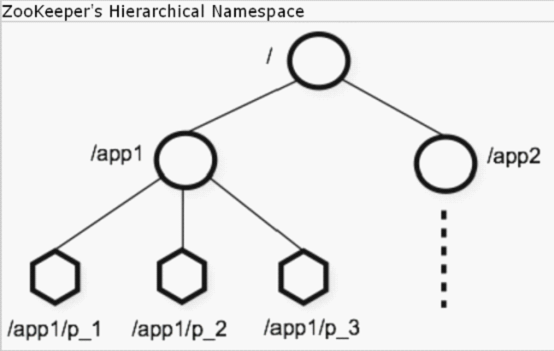
ZooKeeper提供的名字空间与标准文件系统非常相似。名字是一个由斜杠/分隔的路径元素序列。ZooKeeper名字空间中的每个节点都由其路径标识。
3 节点和临时节点
与标准文件系统不同,ZooKeeper名字空间中的每个节点都可以有关联的数据以及子节点。这就像一个允许文件也是目录的文件系统。(ZooKeeper设计用于存储协调数据:状态信息、配置、位置信息等,所以通常存储在每个节点中的数据很小,在字节到千字节范围内)讨论ZooKeeper数据节点时,我们用术语znode来明确指示。
Znode会维护一个stat结构体,其中包含数据和ACL的版本号与时间戳,以便于进行缓存验证和协调更新。每次修改znode数据时,版本号会增长。客户端获取数据的时候,也同时获取数据的版本。
对znode数据的读写操作是原子的。读取操作获取节点的所有数据,写入操作替换所有数据。节点的访问控制列表(ACL)控制可以进行操作的用户。
ZooKeeper具有临时节点的概念。只要创建节点的会话是活动的,临时节点就存在。一旦会话终止,临时节点会被删除。临时节点对于实现tbd是很有用的。
4 条件更新和观察
ZooKeeper支持观察的概念。客户端可以在znode上设置观察。观察将在znode修改时被触发和移除。观察被触发时客户端会收到一个数据包,指示znode已经被修改。如果与ZooKeeper服务之间的连接断开,客户端会收到一个本地通知。这可用于tbd。
5 保证
ZooKeeper非常高效和简单。基于其目标:成为构建如同步这样的更复杂服务的基础,ZooKeeper提供下述保证:
l 顺序一致性:客户端的更新将以请求发送的次序被应用。
l 原子性:更新要么成功,要么失败,没有部分更新。
l 单一系统镜像:无论连接到哪个服务器,客户端将看到一样的视图。
l 可靠性:更新操作的结果将是持续的,直到客户端覆盖了更新。
l 及时性:在某个时间范围内,客户端视图确保是最新的。
关于这些保证的详细信息,以及如何使用这些保证,请参看tbd。
6 简单的API
ZooKeeper的设计目标之一是提供非常简单的编程接口。ZooKeeper仅支持这些操作:
l create:在树中某位置创建一个节点。
l delete:删除一个节点。
l exists:测试某位置是否存在某节点。
l get data:读取节点数据。
l set data:向节点写入数据。
l get children:获取子节点列表。
l sync:等待数据传播。
关于这些操作的更深入讨论,以及如何使用它们来实现更高层的操作,请参看tbd。
7 实现
下图显示了ZooKeeper服务的高层组件。除了请求处理器(Request Processor)之外,组成ZooKeeper服务的每个服务器拥有每个组件的自有拷贝。
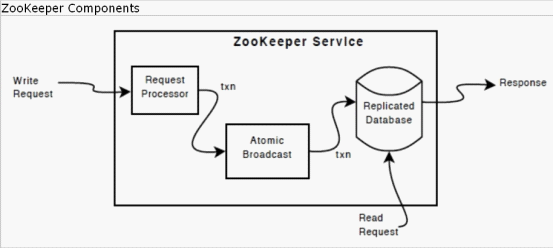
自我复制数据库(replicated database)是一个包含整个数据树的内存数据库。更新会记录到磁盘中以便可以恢复,并且将写操作应用到内存数据库之前会先写入到磁盘。
每个ZooKeeper服务器都为客户服务。客户端连接到一个服务器,提交请求。读请求由每个服务器数据库的本地拷贝进行服务。改变服务状态的请求和写请求由一致性协议处理。
作为一致性协议的一部分,客户端的所有写请求都被转发到单个服务器,也就是领导者。其他ZooKeeper服务器则是跟随者,它们接收来自领导者的建议,对传递的消息达成一致。消息层考虑了替换失败的领导者和跟随者与领导者同步的问题。
ZooKeeper使用定制的原子消息协议。因为消息层是原子的,ZooKeeper可保证本地拷贝不会发散(diverge)。收到写请求时,领导者计算写入操作后系统的状态,将其转换成一个捕获此状态的事务。
8 使用
ZooKeeper的编程接口非常简单。但是,可将其用于实现高层顺序操作,如同步原语、组成员管理、所有者关系管理等。更多信息请参看tbd。
9 性能
ZooKeeper被设计为高性能的。但它真的是高性能的吗?Yahoo研究中心的ZooKeeper开发团队证实了ZooKeeper的高性能,特别是在读操作比写操作多的应用中(见下图),因为写操作涉及在所有服务器间同步状态。(读操作比写操作多是协调服务的典型情况)
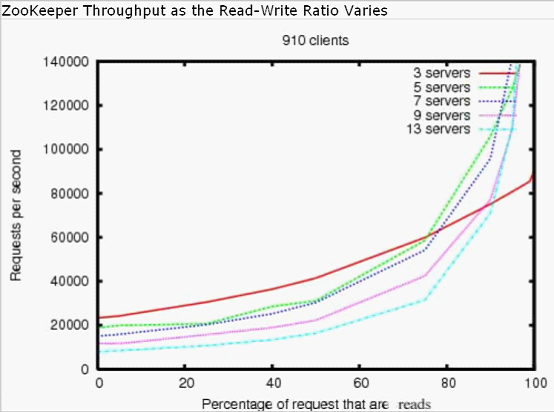
上图是ZooKeeper 3.2在配置有两个2GHz Xeon处理器和两个SATA 15K RPM驱动器的服务器上运行时的吞吐率图形。一个驱动器配置为ZooKeeper日志专用设备。快照写入到操作系统驱动器。读写操作1KB的数据。“服务器数”指的是ZooKeeper集群的大小,即组成服务的服务器个数。大约30个其他服务器用于模拟客户端。ZooKeeper集群配置为不允许客户端连接到领导者。
提示:3.2版的读写性能是3.1版的2倍。
Benchmarks也表明ZooKeeper是可靠的。下图(第10节的图)显示了ZooKeeper在各种失败情况下的反应。图中标记的各个事件是:
1.跟随者失败和恢复
2.另一个跟随者失败和恢复
3.领导者失败
4.两个跟随者失败和恢复
5.另一个领导者失败
10 可靠性
为揭示在有失败注入时系统的行为,我们在一个由7台机器组成的ZooKeeper服务上运行和先前一样的benchmark测试,但是让写操作的百分比固定为30%,这是预期负载比例的保守估计。
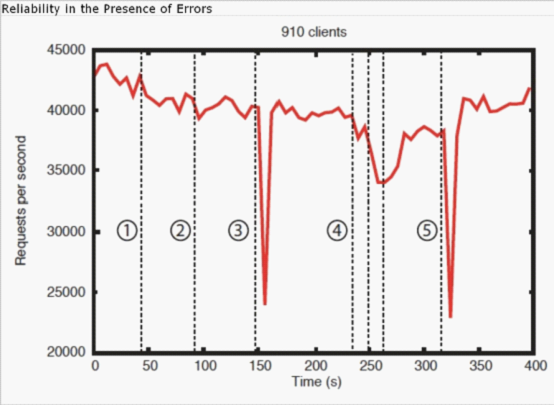
此图有几处值得仔细观察。首先,如果跟随者失败后快速恢复,则ZooKeeper可以维持高吞吐率。但更重要的是,领导者选举算法让系统可以足够快地恢复,以阻止吞吐率有实质性的下降。据我们观察,ZooKeeper选举一个新的领导者的时间小于200ms。第三,一旦跟随者恢复并且开始处理请求,ZooKeeper可以恢复高吞吐率。
11 ZooKeeper工程
ZooKeeper已经在很多工业应用中。Yahoo!在Yahoo! Message Broker中使用ZooKeeper作为协调和故障恢复服务。Yahoo! Message Broker是一个高度扩展的发布-订阅系统,管理着成千上万个需要拷贝和数据传递的话题。Yahoo!的很多广告系统也使用ZooKeeper来实现可靠服务。
我们鼓励用户和开发者加入社区,贡献技能。更多信息请看。
转自 http://s2.sinaimg.cn/orignal/56dee71agb2cbc1946ec1